News du dimanche 19 mai 2024
Les CPU des Mac : Rosetta 2, ARM & Apple Silicon

Un épisode hors-série, entre les années 1994 marquant le passage au PowerPC et l'année 1995 qui verra arriver les premiers clones qui sont d'une certaine façon des "hackintosh", pour décrire ce que fait Rosetta 2 en liaison avec les CPU des Apple Silicon, et pourquoi elles sont conçues pour Rosetta 2 et vice-versa...
Dans le dernier chapitre, je vais pouvoir conclure sur les limites de l'exécution x86 sur ARM contenu dans Windows on ARM, ce qui explique pourquoi les PC ARM étaient très lents, sont encore très lents et pourraient le rester pour les logiciels x86.
Transpilation Quésako?
Il y a différentes façon d'exécuter du code créé pour une autre architecture, et si l'émulation instruction par instruction a été choisi pour le passage du 68k au PowerPC, c'est la transpilation qui a servi lors du passage du x86 à ARM pour Rosetta 2.
La transpilation dans Rosetta 2 consiste à prendre des segments de code x86 d'un logiciel, et d'en transformer chaque instruction en code ARM natif à la première exécution pour recréer de nouveaux segments de code qui sont alors conservés pour ne pas refaire l'opération à chaque lancement du logiciel.
Certaines instructions sont directement transformables, d'autres nécessitent plusieurs instructions ARM pour une instruction x86, mais il peut aussi arriver que plusieurs instructions x86 puissent être regroupées en une instruction ARM.
L'idée étant qu'après la transpilation via Rosetta 2, un logiciel x86 possède le code ARM effectuant les mêmes actions et soit directement exécutable par les SoC Apple Silicon.
L'ordre des octets dans les mots (Endianness)
Correction: on est chanceux, contrairement au passage douloureux du PowerPC au x86, l'architecture ARM 64 bits stocke les octets dans les mots de puis de 8 bits dans le même ordre en mémoire.
Drapeau Parité & sauts indirects
La parité parlera aux plus anciens d'entre vous: c'est le compte de bits à 1 dans un résultat d'opération sur le x86, qui peut être pair ou impair, et qui est stocké dans les drapeaux (Flags).
Pour des raisons historiques en lien avec les liaisons séries, le x86 intègre cela dans son registre d'état, mais pas l'architecture ARMv8.
En théorie, après quasiment chaque opération modifiant le registre d'état, il faudrait regénérer l'état de ce bit dans l'émulateur ou le code transpilé, et le stocker séparément dans un registre, ce qui est très couteux, plus encore que les accès mémoires.
Apple a résolu le problème en ajoutant un mode d'exécution propriétaire et le calcul de ce bit dit P dans un bit inutilisé des drapeaux de ses Apple Silicon, de manière transparente.
Là aussi la transpilation de code x86 nécessite de rajouter du code qui ralentit le fonctionnement, dans le cas ou les drapeaux seraient lus, stockés, etc.
Un exemple typique de code s'amusant (sic) avec les drapeaux (MS-DOS 4.0 devenu open-source).
Addenda: un problème pire est celui du drapeau half-carry (A) nécessitant encore plus de traitements.
Instructions vectorielles AVX, AVX-2 & AVX-512
Là c'est simple, Intel a breveté et verrouille l'usage de ses sous-ensembles d'instructions en refusant toute émulation, quelque soit le moyen technique utilisé. Nada!
Heureusement, si les logiciels peuvent intégrer des instructions AVX, AVX-2 ou AVX-512, ils testent la présence de ces fonctionnalités et aiguillent l'exécution sur du code utilisant des instructions vectorielles plus simples et limitées (SSE 128 bits), ou du code classique non-vectoriel.
Il y a dans ce cas une perte de performance face au code vectoriel, mais l'émulation fonctionne bien, et ces cas sont plutôt rares.
L'efficacité de Rosetta 2
Ici le graphique présentant les performances du MacBook Air M1 fin-2020 avec celles des MacBook Air Intel début-2020, la première ligne est du code ARM natif, tout le reste est du code x86!
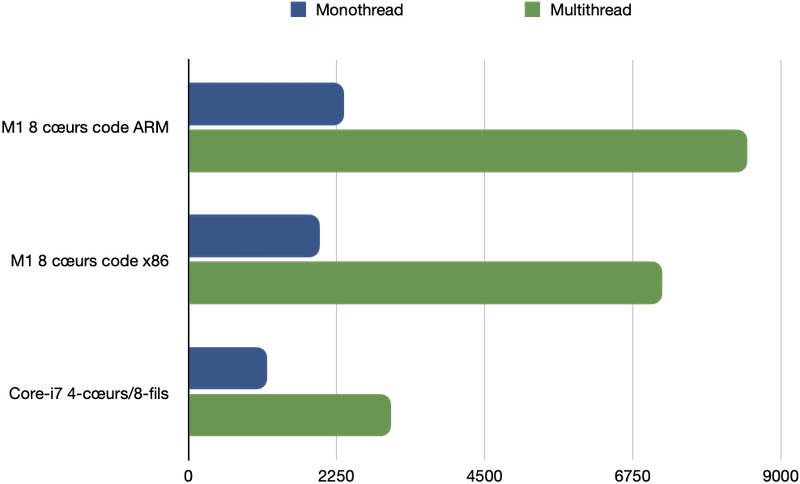
Contrat respecté!
Grâce au gain en performance du M1 face à la CPU Intel qu'il remplace et à l'efficacité de Rosetta 2, le code x86 ne tourne pas aussi vite que sur un Mac Intel sorti 6 mois plus tôt, mais deux fois plus vite!
Tout l'inverse de ce qui avait été observé sur les PC ARM à base de SoC Qualcomm. Mais pourquoi?
Les logiciels x86 sur CPU ARM & Snapdragon X
C'est là tout le problème rencontré par Microsoft avec Windows on ARM WoA, faire tourner les logiciels Windows x86 mais surtout les faire tourner assez rapidement pour contenter la clientèle pendant la transition, alors que nombre d'applications ne sont toujours pas natives, et qu'il restera toujours d'anciens logiciels très utiles qui ne sont plus suivis ni mis-à-jours.
L'exécution x86 au sein de WoA se heurte aux même limites que sous macOS avec les Apple Silicon, limites contournées via des cœurs propriétaires avec des extensions Apple associé à Rosetta 2 tout aussi propriétaire.
Las, les plateformes ARM n'intègrent pas le nouveau mode d'exécution propriétaire à Apple, et donc les performances réelles en sont grandement affectées, là où Rosetta 2 délivre maintenant près de 90% des performances natives, WoA semble être en-dessous des 50%.
Ce qui a été un échec avec les premières plateformes PC Qualcomm, nativement très lents, et encore plus pour les logiciels x86 qui constituaient la presque de la logithèque Windows.
On ne sait pas si Qualcomm a introduit des fonctionnalités qui permettraient ultérieurement d'accélérer cette exécution, ce qui serait fait au mépris des règles d'ARM et sans son consentement, brisant la licence concédée.
En revanche il est certain qu'actuellement WoA n'utilise pas d'instructions ou modes propriétaires Qualcomm pour accélérer cette exécution, ce qui explique les déconvenues avec les nouveaux Snapdragon X benchamrkés par des OEM et un grand constructeur.
Il faut relativiser, car de plus en plus de logiciels Windows sont disponibles nativement pour ARM dont Chrome récemment, l'exécution des applications x86 fonctionne très bien, juste plus lentement, et avec la puissance correcte du Snapdragon X cela ne devrait pas poser de problème hors logiciels particulièrement gourmand.
En conclusion
Rosetta 2 est très performant, il l'était dès les pré-versions de macOS ARM sur le Mac mini DTK à base de A12z destiné aux développeurs.
Ces performances s'expliquent non pas par du génie logiciel, mais par du matériel créé pour cela, les extensions de modes de fonctionnement et d'instructions propriétaires ajoutés par Apple dans ses Apple Silicon.
Alors qu'on avait observé des performances très médiocres sur l'émulation x86 sur les PC ARM à base de SoC Qualcomm, et que cela semble être toujours le cas avec le Snapdragon X, par absence de support matériel et/ou logiciel, sur nos Mac les performances ont été largement préservées.
Ce coup-ci, via le contrôle absolu sur le matériel et le logiciel, Apple a totalement réussi le passage d'une architecture (x86) vers la suivante (ARM). Indolore.
Êtes-vous tenté par le nouveau MacBook Neo ?
Total des votes : 1428